

如果您的代码浪费了 1000 倍以上,为什么在云中节省 30% 毫无意义
总结
当 Kirk Pepperdine 要求开发人员解决涉及 Java 代码片段的性能挑战时,Azul 首席销售工程师 Daniel Witkowski 尝试解决该问题。他发现,挑战与其说在于性能,不如说在于我们的思维方式,因为软件浪费在未被度量之前是不可见的。
在本文中,您将了解:
- 以不同的思维方式看待代码,在性能(以及成本)方面所能带来的提升,往往超过硬件调优
- 许多现实世界的系统表现得就像用整洁代码伪装的隐形低效
- 正则表达式引擎可能会导致严重的性能下降,甚至引发锁定整个线程的“灾难性回溯”
- 有时,使用 JVM 中已有的内容比创建新内容更快、更安全
- 移除方法调用、Unicode 开销和无关检查能够提升性能并节省成本
- 快速失败、首先检查最简单的条件并跳过不必要的工作的代码可能非常有效
几周前,Kirk Pepperdine 发布了一项令人着迷的性能挑战——一段看似微不足道的 Java 代码片段,但却产生了令人费解的运行时行为。
他邀请读者尝试解决这个问题。如果您还没有看到它,请在这里停一下并亲自尝试一下 - 当您完成后,请查看 Kirk 的官方解决方案。
当我看到它时,我认为重新审视一些基础知识将是一个有趣的练习——但我越深入,我就越意识到这不仅仅关于性能。这是关于我们的思考方式。
这让我反思,作为开发人员,我们经常无意识地以效率换取便利,我们在基础设施、计算资源乃至能源上的大量浪费,并非源于糟糕的架构,而是源于那些微小、看似无关紧要的编码决策。
我们都喜欢谈论云成本优化:如何通过调整 AWS 配置或将工作负载转移到(或不转移)竞价形实例来节省 30%、40%,甚至 50%。但我们很少问一个更简单的问题:
如果我们的软件正在浪费的资源已经比应有的量多了 1000 倍,该怎么办?
这才是性能调优的真正要义——不在于追逐毫秒级的提升,而在于发现那些我们对低效视而不见的地方。
1.快速现实检查——编程语言和能源消耗
A remarkable study comparing the energy efficiency of 27 programming languages quantified what many of us intuitively know: language choice matters — not just for speed, but for environmental impact.
| 语言 | 能源使用与 C 语言对比 | 相对性能 | 典型用途 |
|---|---|---|---|
| C | 1 倍 | 基准 | 嵌入式系统 |
| C++ | 1.2 倍 | 接近原生 | 高性能系统 |
| Java | 约 1.5-2 倍 | JIT 编译 | 企业级,后端 |
| Python | 约 50 倍 | 已解释 | 脚本、AI、ML |
| Ruby/PHP | 约 40 倍 | 已解释 | Web 后端 |
这不是拼写错误——对于完全相同的算法,Python 的能耗可能是 C 的 50 倍。Java 介于两者之间——但这只是当我们编写高效代码时的情况。编写不当的 Java 很容易表现得像一个因咖啡因过量而失控的脚本语言。
规模会将一切成倍放大。
即使在拥有高度先进硬件的情况下,Google 也通过优化而非扩展实现了巨大的节省——借助 DeepMind AI,将数据中心的制冷能耗降低了最高 40%,并将整体能耗减少了约 15%。
不是通过购买更多服务器,而是通过更明智地思考现有系统如何使用资源。然而我们中的许多人却做了相反的事情。我们使用动态的解释型语言构建微服务,然后花费数月时间微调自动扩展规则,以保持成本在可接受范围内。我们横向扩展而不是纵向优化,添加节点而不是改进逻辑。
这正是本文的核心——通过以不同的方式思考代码,我们能够在性能(以及成本)方面取得比任何硬件调优更显著的提升。
2.第一步——将异常作为逻辑
初始的未经优化基线如下所示:
public static boolean checkIntegerOrg(String testInteger) {
try {
Integer theInteger = new Integer(testInteger);
return (theInteger.toString() != "") &&
(theInteger.intValue() > 10) &&
((theInteger.intValue() >= 2) && (theInteger.intValue() <= 100000)) &&
(theInteger.toString().charAt(0) == '3');
} catch (NumberFormatException err) {
return false;
}
}
看起来很合理,对吧?如果字符串不是数字,我们会捕获异常并继续进行。看似简单,
但事实并非如此。
在许多输入不是数字的数据集中,此代码的性能非常糟糕。每个无效输入都会触发 NumberFormatException,而 Java 中的每个异常都会带来沉重的代价。引发异常与返回值不同。它会创建一个成熟的对象,捕获堆栈跟踪,并与 JVM 内部同步。CPU 花在记账上的时间多于完成有用工作的时间。
一位同事曾经告诉我,“我们验证层的运行速度慢于数据库查询。”当我查看时,每条不良记录都会引发并记录异常。应用程序并非受制于 I/O,而是受制于异常。这就是许多现实世界系统的表现——用整洁代码伪装的隐形低效。
将异常用于逻辑,就好比为了确认自己是否有脉搏而叫救护车——在技术上虽然正确,但效率极其低下。
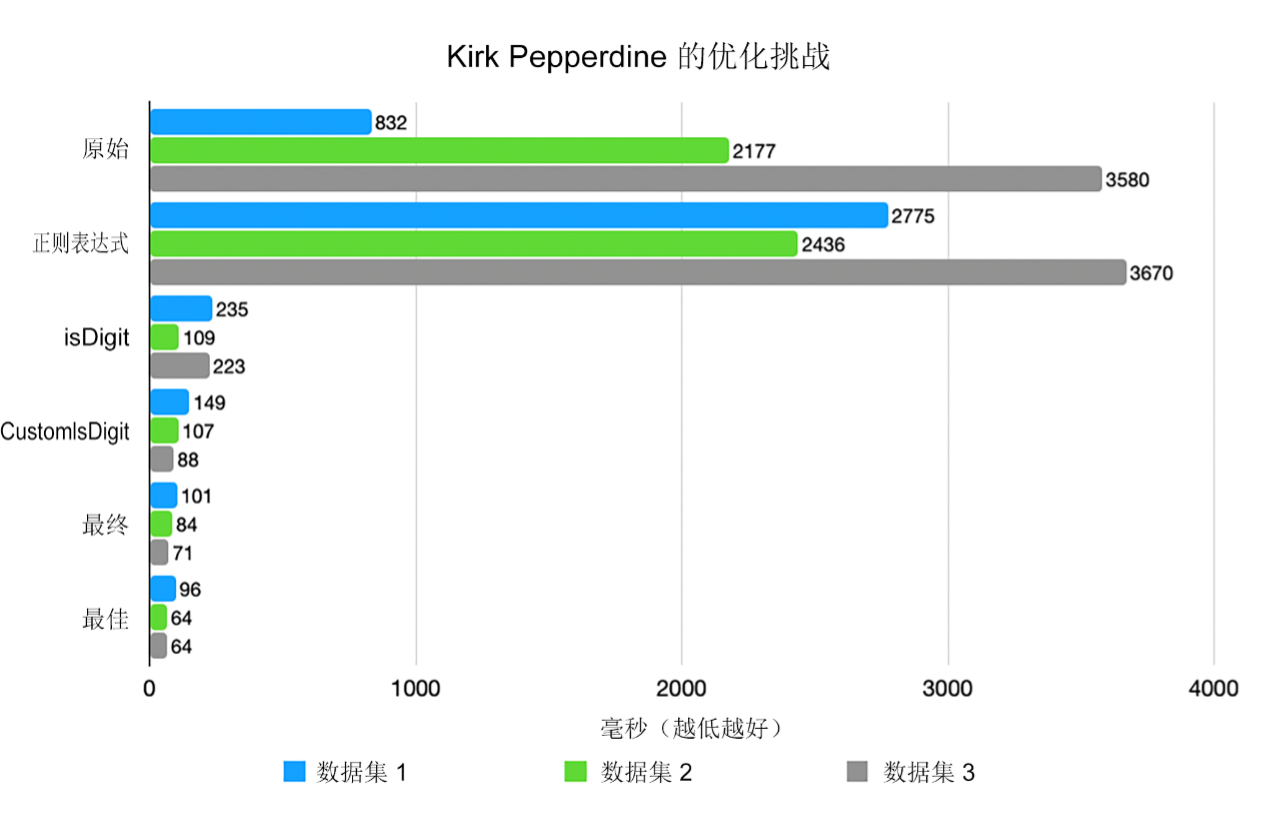
旅程由此开始——三个数据集,每一个都比前一个更混乱,包含更多不正确或格式错误的条目 [图 1]。
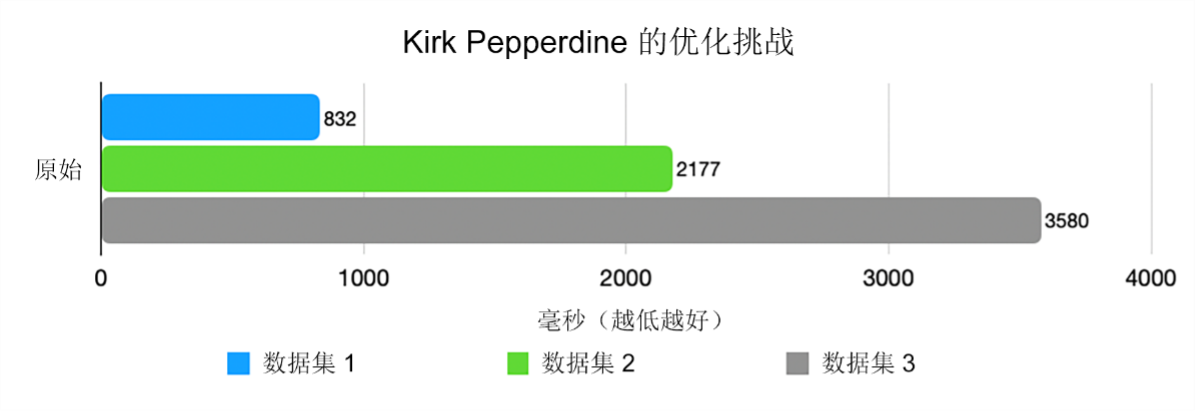
3.尝试二 – 正则表达式陷阱
我决心解决这个问题,于是想到:在解析之前,先对输入进行验证。很自然地,我想到使用正则表达式:
public static boolean checkIntegerRegExp(String testInteger) {
try {
if (testInteger.length() > 6) return false;
if (!testInteger.matches("^\\d{1,6}$")) return false;
Integer theInteger = Integer.valueOf(testInteger);
int val = theInteger.intValue();
return (val > 10) && (val <= 100000) && (testInteger.charAt(0) == '3');
} catch (NumberFormatException err) {
return false;
}
}
它看起来既优雅又安全。结果却更慢。慢得多 [图 2]。
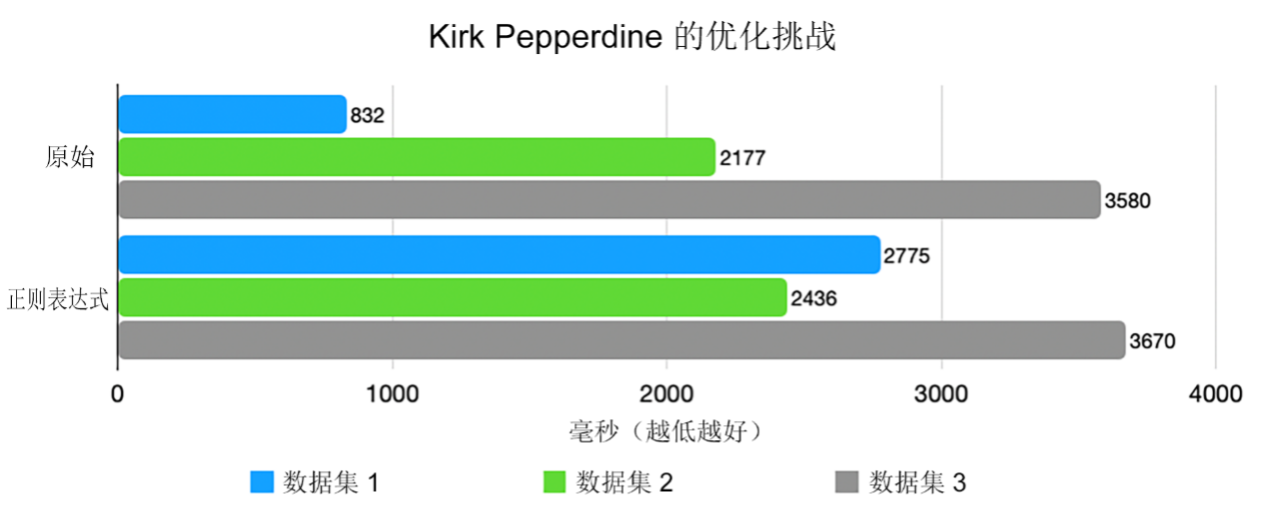
为什么正则表达式可能成为特洛伊木马
为什么?因为每次 matches() 运行时,它都会在后台启动一个微型状态机——解析模式,编译它,创建一个匹配器,逐个字符地遍历输入。如果您在热路径中执行此操作(例如验证、解析或请求过滤),那么您的 CPU 会花费更多时间来解码正则表达式语法,而不是检查实际字符。
Jeff Atwood 早在他的博客文章《Regex Performance》(正则表达式性能)中就对此发出过警告。他指出,正则表达式引擎可能会轻松导致严重的性能下降,甚至引发锁定整个线程的“灾难性回溯”。
在我自己的一个项目中,一个旨在过滤无效 ID 的正则表达式在高负载下变成了 CPU 熔炉。将其替换为简单的字符循环可将 CPU 时间减少 90%。正则表达式很方便。
正则表达式就像 SQL 中的通配符,对于少量记录来说没问题,但大规模时就很危险,在实际生产代码中会表现出数量级的速度减慢。
4 第三步 – 让 CPU 喘口气
接下来,我尝试了一些更简单的方法。如果我们只使用 Java 已经提供的功能——没有正则表达式魔法或异常陷阱,会怎么样?
public static boolean checkIntegerIsDigit(String testInteger) {
if (testInteger.length() > 6)
return false;
if (testInteger.charAt(0) != '3')
return false;
for (int i = 1; i < testInteger.length(); i++) {
if (!Character.isDigit(testInteger.charAt(i))) return false;
}
int val = Integer.parseInt(testInteger);
return (val > 10) && (val <= 100000);
}
性能立即提高了一个数量级 [图 3]。
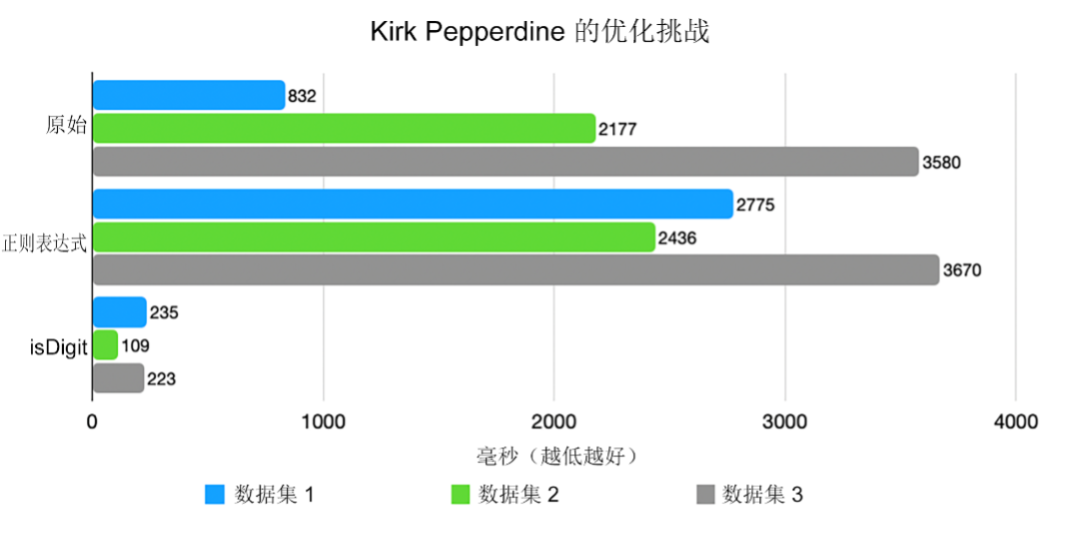
为什么?因为 CPU 喜欢可预测性。
逻辑很简单且可预测。分支很容易推测,内存访问是顺序的,并且不存在隐藏的分配。没有异常,没有正则表达式引擎,没有对象创建。只是干净、确定性的工作。
了解您的语言已经提供的功能是值得的。
另一条经验教训:了解您的标准库。诸如 Character.isDigit() 或 Integer.parseInt() 之类的方法存在自有其原因——它们通常由那些在 JVM 上耗费多年时间、致力于压榨出每一个纳秒性能的工程师编写。您并不总是需要重新发明轮子。有时,利用现有的功能不仅更快,而且更安全。
虽然并不完美,但它们对于大多数情况来说已经足够好了,可以让您快速创建高性能、可维护的代码。
正如一位高级工程师曾经告诉我的:
“好的代码并不是通向答案的最短路径,而是对 CPU 和开发人员来说惊喜最少的路径。”
5.第四步——手工打造的精确性
但我想知道自己能够走到多远。于是我甚至去掉了内置函数,编写了自己的版本:
public static boolean checkIntegerCustomIsDigit(String testInteger) {
if (testInteger.length() > 6)
return false;
if (testInteger.charAt(0) != '3')
return false;
for (int i = 1; i < testInteger.length(); i++) {
char c = testInteger.charAt(i);
if (c < '0' || c > '9') return false;
}
int val = fastParseInt(testInteger);
return (val > 10) && (val <= 100000);
}
public static int fastParseInt(String s) {
int num = 0;
for (int i = 0; i < s.length(); i++)
num = num * 10 + (s.charAt(i) - '0');
return num;
}
这个手工制作的版本的运行速度大约为 Character.isDigit() 的 2 倍。为什么?没有方法调用,没有 Unicode 开销,没有无关的检查 [图 4]。
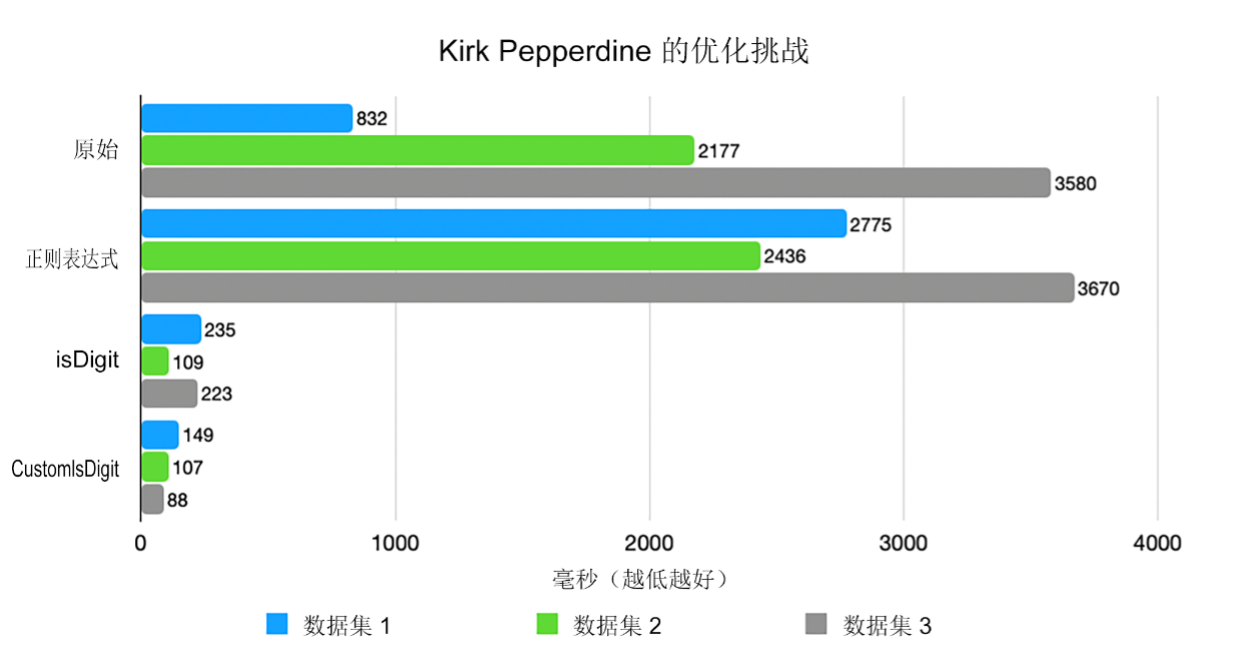
但这种改进是有代价的。这段代码的通用性较差,前瞻性不足,并且在可读性上稍显欠缺。我在生产环境中也见过类似的模式。在某个低延迟的金融系统中,我们在关键路径上替换了 Integer.parseInt(),该路径每秒需要处理数百万条消息。每百万条消息的增益为 300 毫秒。在单独使用时微不足道,但在全球规模下却具有变革性。
然而,精确与执念之间仍然存在微妙的界限。有时,最优化的代码也是最难维护的。优化应当服务于系统,而不是服务于个人的自负。
这种程度的优化在何时才有意义?
- 热路径:解析数百万条记录、网络验证或数据提取。
- 已知限制:ASCII 数字,固定长度。
- 在大规模系统中:微小的低效会被无限放大。
不过,这种优化是有代价的:更复杂,通用性更低。应当有意识地使用它们,而不是习惯性地依赖。
6.第五步——更快地失败,更聪明地思考
最终,我构建了一个快速失败的版本,首先检查最简单的条件,并跳过不必要的工作。
public static boolean checkIntegerFinal(String testInteger) {
if (testInteger.length() > 5 || testInteger.length() < 2)
return false;
if (testInteger.charAt(0) != '3')
return false;
for (int i = 1; i < testInteger.length(); i++) {
char c = testInteger.charAt(i);
if (c < '0' || c > '9') return false;
}
return true;
}
该版本的性能可达原始版本的 10 倍到 50 倍,几乎与 Kirk 自己展开的 switch-case 变体(在图 5 中标记为“最佳”)相当。
在那一刻,我意识到了一点:优化的过程本身所带来的启示,往往比最终结果更为深刻。每一步(异常删除、正则表达式替换、循环简化)都剥去了层层浪费。结果不仅仅是更快的代码,而是更清晰的思维方式。
7.效率经济学
云计算为我们提供了无限的可扩展性,也带来了忽视浪费的无限诱惑。
- 我们通过增加硬件来解决问题。
- 我们选择自动扩缩,而不是进行深入分析。
- 我们“监控”低效率,而不是将其消除。
但低效率并不会在云中消失,反而会成倍增加。每个额外的 CPU 周期都会在数十个区域的数千台机器上运行。
我们横向扩展而不是优化。我们选择“自动修复”,而不是真正理解问题。我们依赖更大的机器而不是更好的代码。
降低云成本的最简单的现实方法之一不是重写代码,而是在更好的运行时上运行它。以大型 Kafka 部署为例。在 Azul 自己的基准测试中,与原生 OpenJDK 相比,在相同的 P99 延迟 SLA 下,Azul Platform Prime 上的 Apache Kafka 的最大吞吐量高出约 45%,可用容量高出约 30%。如果保持相同的工作负载和 SLA,这一性能余量意味着完成相同工作所需的代理数量减少约 30–40%,因此 Kafka 基础设施成本(计算、存储、网络和运营开销)也相应降低 30–40%。换句话说,仅仅切换 JVM 就能带来那种节省效果,而这通常是大多数团队需要花费数月,通过实例调优和预留容量谈判才能实现的。
被 Facebook 收购后,WhatsApp 仅用 35 名工程师就为超过 4.5 亿用户提供服务。这不是魔法,而是工程上的自律、对效率的执着,以及为并发优化的运行时。
效率扩展的是人员,而不仅仅是服务器。
成本最低的优化是在部署之前完成的优化。
隐性的能源账单
计算即能源。低效的软件会在无声中增加碳足迹。
经过优化的代码不仅成本更低,也更环保。云效率和可持续性始于键盘,而不是账单面板。
8.艺术,而非算法
性能调优与其说是语法问题,不如说是工艺问题。这关乎好奇心、对细节的关注,以及对机器的尊重。这关乎于发现精确之美与动作简约之美。
一段调优得当的函数,就像一首俳句:简洁、平衡、表意明确。
真正的性能优化工作,不在于节省毫秒级时间,而在于编写代码时的审慎思考。
Knuth 撰写了《The Art of Computer Programming》(计算机程序设计艺术),而不是《The Science of Computer Programming》(计算机程序设计科学),这是有原因的:科学界定了哪些事可能实现,而艺术则决定了哪些事值得去做。
每项优化都会产生成本。关键在于知道哪些成本值得付出。 .
9.结语——代码如工艺
我的最终实现并不完美。Kirk 的实现仍然快了一点。但这不是重点。关键在于,软件的浪费在被度量之前是不可见的。我们已经将低效常态化,因为云计算用弹性将其掩盖。我们称之为“弹性”,但它往往只是过度配置。
一位导师曾经告诉我,
“如果你能用钱解决性能问题,那么问题并没有得到解决——而是被推迟了。”
他是对的。如果您的代码浪费了 1000 倍的资源,那么节省 30% 的云账单并没有多大意义。优化并不为时过早,而是有意为之。
关键不在于完美,而在于觉察。所以下次部署服务时,问问自己: sk yourself:
- 这段代码中有多少真正需要运行?
- 多久运行一次?
- 成本是多少——CPU、内存还是能源?
归根结底,性能调优不仅是技术问题,更是伦理问题。关键在于以尊重的态度使用资源——为了您的用户、您的公司,以及整个地球。
性能调优的艺术在于认识到:效率即优雅。


