
基于 OpenJDK 的 Azul Zulu Prime(之前称为“Zing”)是 Azul Platform Prime 产品的组成部分,包含一些关键增强功能,以提供更出色的性能。仅举几例,我们的Falcon JIT 编译器可以生成更快的机器代码,C4 无暂停垃圾回收器可以消除停止所有处理的 GC 暂停。虽然我们推荐您继续阅读关于 Platform Prime 如何提高 Apache Kafka 运行速度的内容,但您也可以自己尝试一下。
我们继续阅读衡量 Azul Platform Prime 与 vanilla OpenJDK 性能对比的系列文章。在之前的文章中,我们探讨了 Renaissance 基准测试和 Apache Solr。今天,我们来看看 Apache Kafka,它是现今 Java 社区中最受欢迎的事件流平台。随着事件驱动型架构的兴起,Kafka 代理通常充当整个应用程序的中枢神经系统。因此,它需要处理大吞吐量(每秒事件数),同时保持“合理”延迟。因此,提高 Kafka 集群的吞吐能力成为运行 Kafka 集群的团队的一大关注点。 在本博客文章中,我们将展示底层 JVM 的简单切换可以通过极少的工程设计工作量对 Kafka 吞吐量产生巨大影响。此外,我们还将探讨延迟场景中可能获得的收益;我们将讨论 Kafka 的典型瓶颈,以及如何改进,使它成为低延迟的消息代理
Apache Kafka 测量方法
我们的 Kafka 端到端基准测试可以测量生产者和使用者在 Kafka 集群上的吞吐量。我们运行 3 个 Kafka 代理节点和 1 个 Zookeeper 节点,并且还在 Zookeeper 节点上运行基准测试本身。下面的示意图概述了基准测试拓扑结构。
硬件配置如下表所示:
| AMI | ami-0747bdcabd34c712a (Ubuntu 18) |
| Zookeeper 实例 | c5.2xlarge (1 GB Java 堆) |
| 代理实例 | 3x i3en.2xlarge (40 GB Java 堆) |
| 负载生成实例 * | m5n.8xlarge |
我们在实例上执行的唯一 OSS 配置是配置透明大页,因为我们用它观察到的效果最好:
$ echo madvise | sudo tee /sys/kernel/mm/transparent_hugepage/enable
$ echo advise | sudo tee /sys/kernel/mm/transparent_hugepage/shmem_enabled
$ echo defer | sudo tee /sys/kernel/mm/transparent_hugepage/defrag
$ echo 1 | sudo tee /sys/kernel/mm/transparent_hugepage/khugepaged/defrag对于 Kafka 配置,我们使用了以下参数:
| partitions | 3 |
| replicationFactor | 3 |
| producerThreads | 3 |
| consumerThreads | 3 |
| acks | 1 |
| messageLength | 1000 |
| batchSize | 0 |
| warmupTime | 600s |
| runTime | 600s |
Apache Kafka 在 Azul Platform Prime 上与在 vanilla OpenJDK 上的性能对比基准测试结果
吞吐量
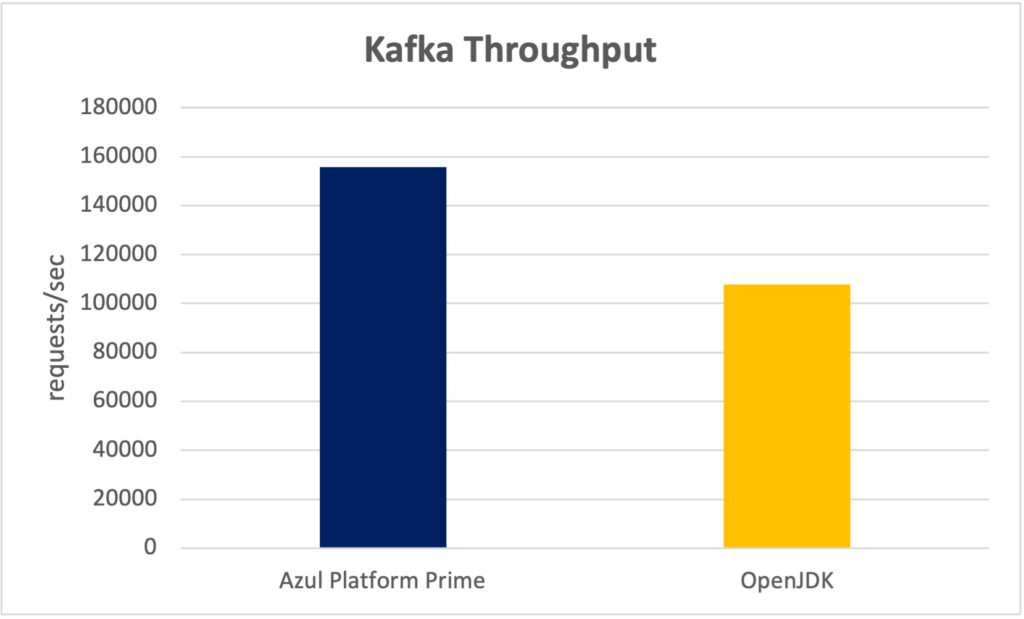
我们通过将服务器上的负载每秒增加 5000 个请求来测量最大吞吐量,直到 Kafka 无法达到更高的负载。测试得到的最大吞吐量如下:
Kafka 最大吞吐量(请求数/秒)
| Azul Zulu Prime | 155,797 |
| OpenJDK | 107,805 |
延迟
在典型的 Apache Kafka 用例中,用户关心的是系统可以处理多少事务同时仍能“良好”运行。“良好”的定义可能有所不同,但在一般意义上,是指处理的延迟保持在可接受的 SLA 之下。根据市场研究,我们将 Kafka 的“良好”运行的定义为较高的百分位数 (P99) 保持在 200 毫秒以下,这仍然能为实时系统提供保证。
根据该定义,我们使用了与上述相同的基准测试、相同的设置和相同的配置。我们修复了在 vanilla OpenJDK 和 Azul Platform Prime 上运行的 Kafka 的吞吐量,并测量了端到端延迟。如果延迟仍然低于定义的水平(200 毫秒),我们会增加吞吐量并重复。
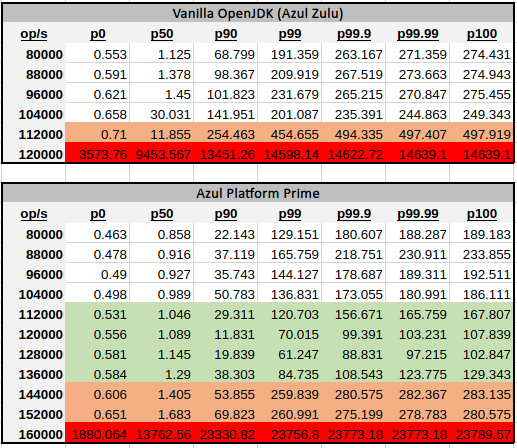
从上表中您可以看出,在 Azul Platform Prime 上运行 Kafka 可以实现每秒多达 13.6 万次操作,同时延迟仅略高于 200 毫秒,相比之下,OpenJDK 仅有 10.4 万次操作,而延迟则从一开始就接近上限。只需简单地切换 JVM,系统的可用容量就提高了30%。
为了更全面地说明,可以看到的是,在吞吐量更高时,Azul Platform Prime 仍能继续“尚且良好”地运行,直到每秒 15.2 万次操作,延迟才开始飙升。相比之下,vanilla OpenJDK 运行的延迟在每秒 12 万次操作时已达到极限。
更细心的读者可能会对更高百分位数的相似性感到好奇 – P99 与最大值之间并没有太大区别。这并非延迟行为方式的典型情况,而且这表明系统的瓶颈是在应用程序本身以外的其他位置。我们在下面进一步深入探讨,但长话短说 - 磁盘速度和文件系统的选择对 Kafka 而言极为重要。
经验教训
磁盘速度对于 Apache Kafka 至关重要
在基准测试过程中,我们意识到 Apache Kafka 就是我们所说的受磁盘 I/O 约束的工作负载,即磁盘速度通常是限制因素的工作负载。毕竟,在 Kafka 的官方文件中也直接提到了这一点:
磁盘吞吐量非常重要。我们拥有多个 8×7200 rpm SATA 驱动器。通常,磁盘吞吐量是性能瓶颈,因此磁盘数量越多越好。更昂贵的磁盘不一定能带来更好的性能,这取决于配置刷新行为的方式(如果您经常强制刷新,则 RPM 更高的 SAS 驱动器可能更好)。
Kafka 使用磁盘作为日志段的存储。每当日志段更新滚动到新的空日志时,应用程序线程就会停滞,从而引入延迟峰值(Kafka 的官方 JIRA 中描述的一种现象)。下面的图表展示了延迟峰值与刷新的磁盘之间的相关性。注:这些图表来自不同的诊断运行,与上述基准测试没有直接关系。
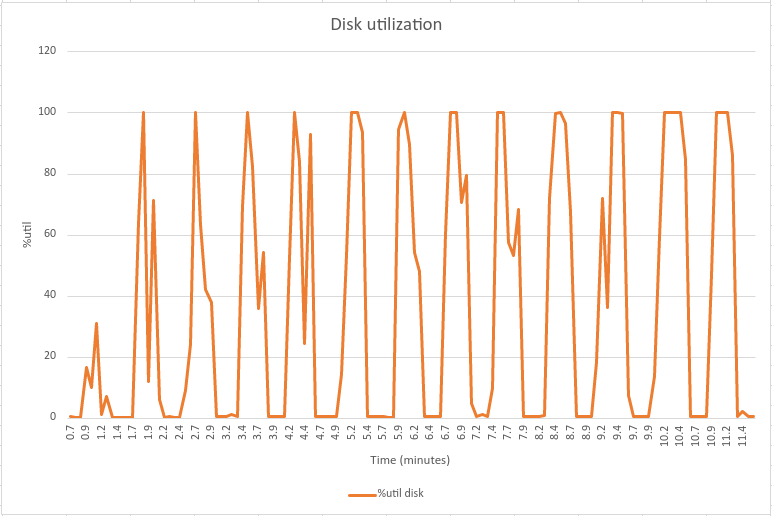
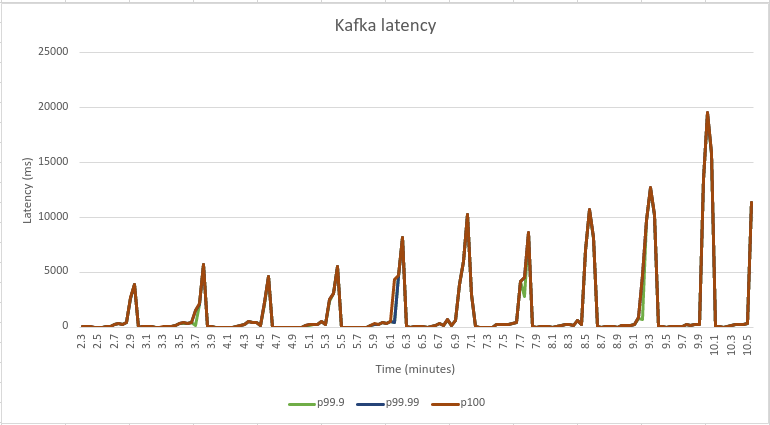
这些图表的数据是使用 Linux 工具 sar(有关更多详细信息,请参阅 sar 文档)收集的。您可以看到,每当 Kafka 的端到端延迟出现延迟峰值时,磁盘 I/O 活动也会增加。
这明确地告诉我们,在运行 Apache Kafka 时须注意磁盘性能,因为磁盘性能对性能有很大影响。因此,我们使用了 i3en AWS 实例类型,它们针对具有快速磁盘的 I/O 进行了优化。
文件系统的选择对于 Apache Kafka 非常重要
如果您阅读了上面的部分,那么您可能并不会奇怪为什么文件系统的选择是一个关键因素。当我们尝试复制 Confluent 的延迟基准测试时,最初我们很难在绝对延迟方面获得相同结果。查看图表,我们可以看到第 99.9 个百分位数的中心数据是 18 毫秒,而我们看到相同的百分位数持续上升,甚至达到 300-500 毫秒。
经过深入调查,我们考虑将文件系统从 ext4(它是 Ubuntu 中的默认文件系统)更改为 xfs。出乎意料地,我们开始得到相同结果 – 这相当于一个数量级的改进!
更出色的是,现在我们消除了磁盘 I/O 瓶颈,Azul Platform Prime 可以真正大放异彩。下面是复制确切延迟场景的图表。
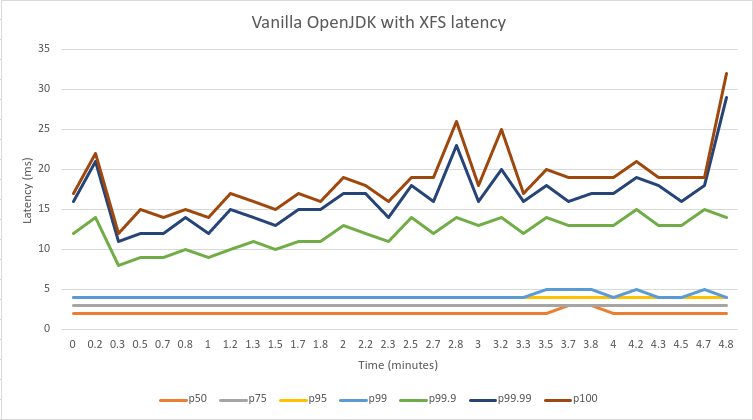
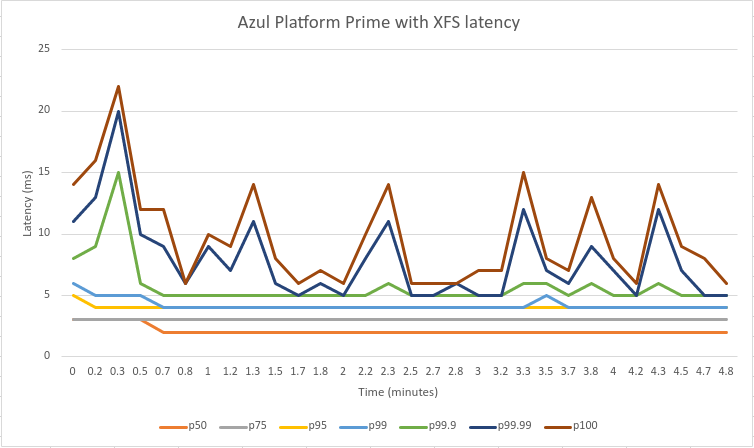
您可以清楚地看到,从第 99.9 个百分位数及以上的所有高百分位数实际上都减少了一半,大部分是以毫秒为单位。因此,我们在 Confluent(不是我们的)官方基准测试中证明,结合 Azul Platform Prime,Apache Kafka 可以成为真正低延迟系统的骨干。
实际投资回报率 (ROI):减小 Kafka 集群规模可以节省资金
Kafka 集群,可以承载与 vanilla OpenJDK 上包含五个节点的 Kafka 集群相同的负载。这就减少了两个一直运行的节点。
我们可以以此计算直接节省的资金:
| vanilla OpenJDK | 说明 | Azul Platform Prime |
| 0.904 美元 | AWS EC2 i3en.2xlarge 每小时价格 | 0.904 美元 |
| 7919.04 美元 | 每年价格(1 个节点) | 7919.04 美元 |
| 5 | 集群中需要的节点数量 | 3 |
| 39595.2 美元 | 每个集群的总价格(每年) | 23757.12 美元 |
| 总成本节约 | 15838.08 美元 |
不难看出,可能节省的成本并非少到可以忽视。值得注意的是,通过底层 JVM 的简单切换,即可实现成本的节约。与其他技术(如按需扩展、投资应用程序代码优化或调整 Apache Kafka 本身)相比,这种方法相对简单。
总结
在本博客文章中,我们展示了 Azul Platform Prime 上使用 Apache Kafka 性能进行的一些实验,并将 Platform Prime 与 vanilla OpenJDK 进行了对比。我们在吞吐量和延迟方面都实现了大约 40% 的性能改善。所有这些结果都被转化为一个实际计算示例,展示用户优化 Kafka 集群规模需要花费多少资金。我们认为,将 JVM 切换到 Azul Platform Prime 是实现这一目标的最简单方法之一。最后,我们分享了从测试工作中吸取的一些经验教训。
Azul Platform Prime 可以通过所谓的 Stream 版本免费获得,用于测试和评估目的。了解这些优点的最简单方法是下载该版本并亲自尝试。请务必顺便访问 Prime Foojay 社区论坛,向我们提供您的测试和评估结果。


