



At Azul, we have been measuring the performance of popular Java open-source projects on our optimized Azul Zing Builds of OpenJDK (Azul Zulu Prime) versus vanilla Azul Zulu Builds of OpenJDK (Azul Zulu). Today we look at throughput measurements with Solr, a popular open-source Java-based search engine.
Azul Zulu Prime (formerly known as “Zing”) is a part of the Azul Prime offering. Azul Zulu Prime is based on OpenJDK, and enhanced with performance, efficiency, and scaling features including the Falcon JIT Compiler, the C4 Pauseless Garbage Collector, and many others. We compare Solr throughput on Azul Zulu Prime with Solr throughput on “unimproved” OpenJDK and use Azul’s Zulu builds of OpenJDK as a basis for OpenJDK measurement.
Measurement Methodology
Following a common practice in benchmarking search engines, we use a 50GB data dump from Wikimedia as the data set, with some post-processing done to make it easier to search. Once indexed, the index size for this data set was around 15GB. See the Solr Throughput Benchmark for a link to the processed data dump and the full instructions on running the tests yourself on AWS.
We tested different types of select queries to see if the difference in performance was more pronounced for more complex queries.
JDK versions tested:
- Azul Zulu Prime 21.07.0.0 – zing21.07.0.0-3-ca-jdk11.0.12
- Azul Zulu JDK 11.0.12 – zulu11.50.19-ca-jdk11.0.12
Solr configuration:
- 4 Solr nodes
- m5.8xlarge AWS instances
- Xmx=60G
- 2 shards with a replication factor of 2
- 3 Zookeeper nodes
- m5.large AWS instances
- Xmx=3G
Client node configuration:
- m5.8xlarge AWS instance
All the nodes were run with minimal additional tuning. We configured the caches to keep doc IDs in the cache but to not aggressively keep the whole doc in cache.
Benchmark Results
Our experiments showed that Azul Zulu Prime throughput was from 29% to 37% faster depending on the query being tested.
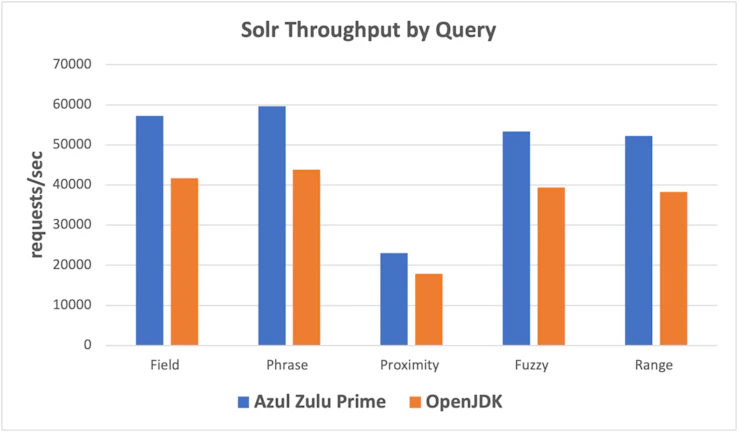
Total Throughput (requests/second)
| Query | Azul Zulu Prime | OpenJDK | Ratio |
| Field | 57214 | 41675 | 137% |
| Phrase | 59654 | 43869 | 136% |
| Proximity | 23019 | 17895 | 129% |
| Fuzzy | 53341 | 39356 | 136% |
| Range | 52251 | 38323 | 136% |
Try It Yourself
Azul Prime Stream Builds are free for testing and evaluation. Try it yourself.


