
总结
传统的 Java 以较慢的解释模式执行代码(被称为 Java 预热),直到它能够构建优化配置文件。这意味着它只有在应用程序处理流量并触及关键代码路径后才能开始优化。正当您为了应对流量激增而进行横向扩展时,机器却处于运行最慢的状态,在处理请求和执行高开销的 JIT 优化之间分摊有限的 CPU 资源
您可以在 AWS 上使用 Azul Optimizer Hub,通过改进 JVM 的工作方式来提升 Java 应用的性能。在这篇文章中,您将了解改进 JVM 将如何帮助您:
- 通过复用先前运行的信息,在代码真正需要之前提前编译,从而缩短 Java 预热时间
- 将 JIT 编译任务卸载到单独的专用 JIT 集群,以便将 CPU 资源充分用于应用程序设计目标所对应的任务
- 通过执行更多资源密集型 JIT 编译,让代码运行速度更快。而这在客户端 JVM 资源有限的情况下,是常规方式难以实现的gned for
Cloud DevOps 团队和工程团队使用 Azul Platform Prime 来减少云浪费并利用已承诺的云支出,同时提高承载能力并保持服务水平应对日益增长的工作负载。Platform Prime 包括以下组件:
OpenJDK 的 Azul Zing 构建版本
OpenJDK 的 Azul Zing 构建版本 (Zing) 是基于 OpenJDK、符合 TCK 标准的现代 Java 运行时。您无需重新编译代码即可使用 Zing 运行 Java 工作负载。Zing 具有以下优势:
- 借助 C4 无暂停垃圾收集器,降低延迟异常值
- 借助 Falcon JIT 编译器,提高吞吐量并降低中位延迟
- 借助 ReadyNow 预热优化器和云原生编译器,缩短 Java 预热时间并减少去优化次数
Azul 优化器中心
Azul Optimizer Hub 是一组可扩展的服务,可部署在虚拟私有云 (VPC) 中的 Kubernetes 上。凭借 Optimizer Hub,Java 应用程序可以更快地达到全速运行,同时最大程度地降低客户端 CPU 负载。Optimizer Hub 提供两项服务来解决传统的 Java 预热问题:
- ReadyNow Orchestrator:监控整个实例集的使用模式,以构建优化配置文件来驱动 JVM 上的编译。新启动的 JVM 会跳过性能分析阶段,在初始化后立即编译方法,从而使大部分 JIT 编译工作在应用程序初始化期间进行,然后再处理流量。
- 云原生编译器:通过将 JIT 编译任务卸载到单独的专用 JIT 集群,提供服务器端优化。云原生编译器会缓存优化结果,避免数百次重复相同的优化操作,从而使客户端能够将 100% 的 CPU 资源用于处理请求,而无需为初始 JIT 编译峰值预留容量。
运行 Optimizer Hub 的 Amazon Services
AWS 上使用 Optimizer Hub 的完整 Java 系统可能包含以下环境。
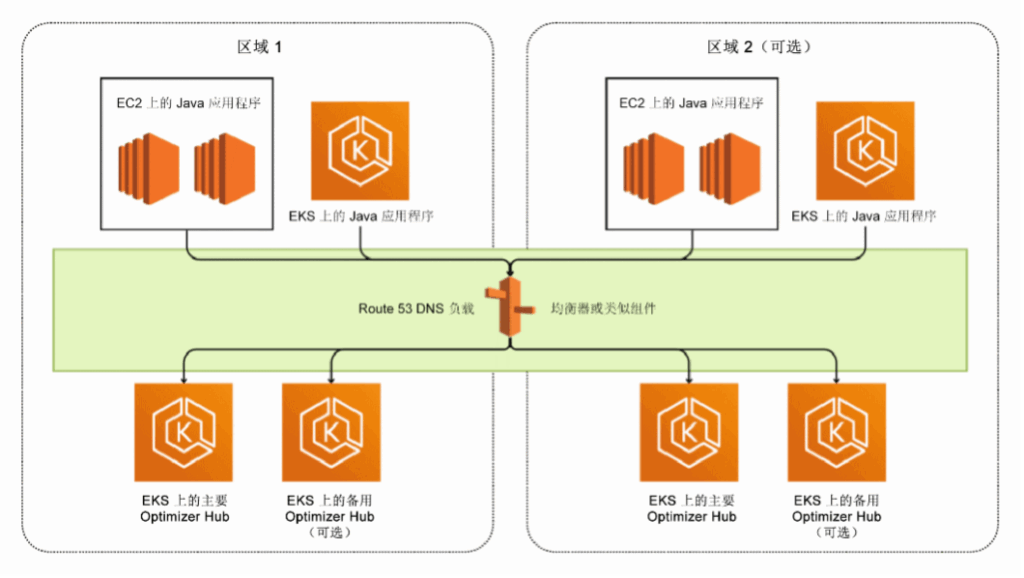
将 EC2、EKS 或 Fargate 上运行的实例上的 Java 虚拟机(Oracle、OpenJDK、Corretto)替换为 Zing。然后,Zing 与距离最近的 Optimizer Hub 实例进行通信。每个 Optimizer Hub 实例都是一个共享服务,可以为数千个 Java 应用程序提供服务。
在上图中,您将 EC2、EKS 或 Fargate 上运行的实例上的 Java 虚拟机(Oracle、OpenJDK、Corretto)替换为 Zing。Zing 与距离最近的 Optimizer Hub 实例进行通信。每个 Optimizer Hub 实例都是一个共享服务,可以为数千个 Java 应用程序提供服务。
您的应用程序和其他 Java 系统
除了您自己编写的应用程序之外,Apache Kafka 等第三方应用程序也可以从 Zing 和 Optimizer Hub 中受益。所有这些都可以通过可用选项(例如 EC2 实例、Elastic Container Service (ECS)、Elastic Kubernetes Service (EKS) 等)之一部署在 AWS 上。
其中许多应用程序可以在基于 Graviton 的系统上运行,与基于 Intel 的系统相比,这种系统更加经济高效。
EKS 上的 Optimizer Hub
Optimizer Hub 可以在任何兼容 x86 Kubernetes 的系统上运行,因此 AWS EKS 是部署它的完美环境,同时考虑到以下系统要求:
- 实例类型:按需或预留 EC2 实例(无竞价型实例)
- 规模评定:每个节点至少有 8 个 vCore 和 32GB RAM
- 推荐实例:m6 或 m7 实例系列
您可以使用现有的 Kubernetes 集群,也可以使用 AWS‘eksctl’工具和所提供的配置文件创建一个新集群,这些文件记录在 EKS 上的集群配置中:
eksctl create cluster -f opthub_eks.yaml Azul 在安装 Optimizer Hub 中提供了在此 EKS 集群上安装所有 Optimizer Hub 组件的详细分步说明。接下来,如果要修改一些配置文件,只需要执行几条命令:
helm repo add opthub-helm https://azulsystems.github.io/opthub-helm-charts/
helm repo update
kubectl create namespace my-opthub
helm install opthub opthub-helm/azul-opthub \
-n my-opthub \
-f values-override.yaml 将应用程序连接到 Optimizer Hub
一旦 Optimizer Hub 实例在您的环境中可用,您就可以指示任何 Java 应用程序连接到它以存储或获取 ReadyNow 配置文件,并卸载其编译:
java -XX:OptHubHost=<host>[:<port>] <other-options> -jar yourapp.jar Java 预热改进结果
根据 Zing 提供的扩展垃圾收集器日志,我们可以深入了解在不使用或使用云原生编译器的情况下运行的示例应用程序的行为。下图为 GC Log Analyzer 的屏幕截图,这是 Azul 开发的一款工具,用于可视化垃圾收集器日志文件和 ReadyNow 配置文件中的数据。Zing 生成的 GC 日志文件除了有关垃圾收集器的信息之外,还包含有关编译和运行时其他行为的更多信息。
该应用程序是运行在 Kubernetes 上的 8 vCore 容器中的电子商务应用程序。就绪检查配置为在运行后 90 秒开始,以便在流量开始之前有时间初始化应用程序并预热尽可能多的重要 Java 代码。我们的目标是:
- 通过提前完成 JIT 优化来减少就绪等待时间
- 减少客户端在 SLA 内提供流量服务所需的 vCore 数量
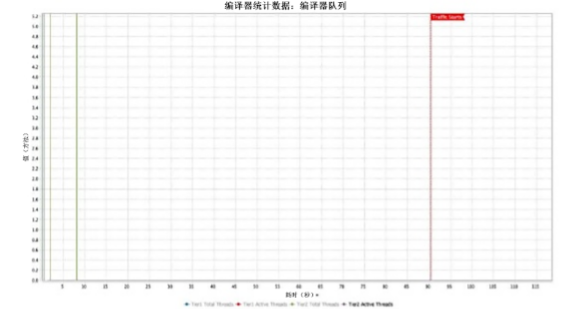
编译器队列
编译器队列图显示 JVM 必须处理多少工作才能根据代码的使用方式将 Java 字节码编译为其运行系统的最佳本机代码。
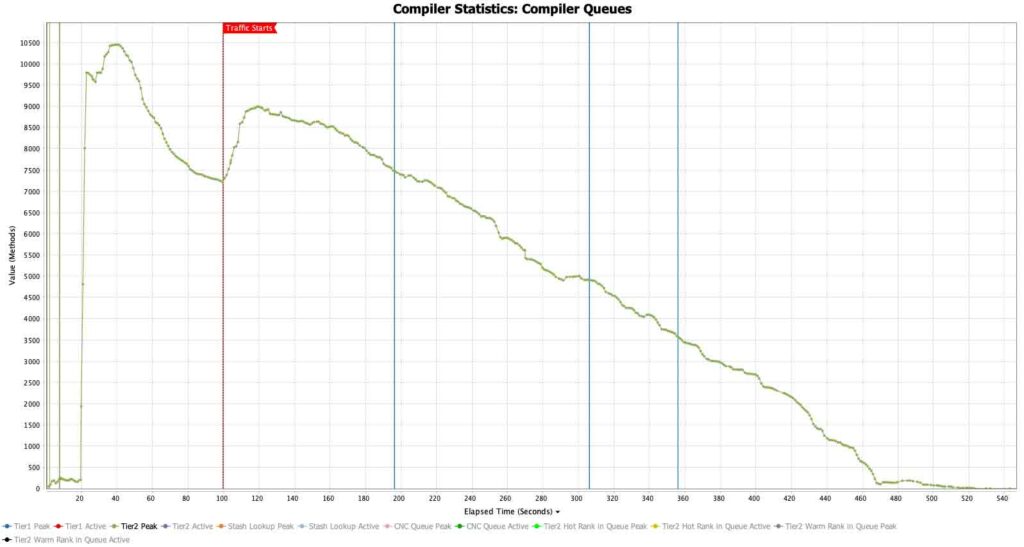
在第一个图表中,加载运行时大约需要 20 秒,然后开始编译应用程序代码 [图 1]。在流量开始之前,编译量的瞬时激增是 ReadyNow 的优势之一。通常,OpenJDK 仅在流量开始后才开始编译。另一方面,ReadyNow 可以在流量开始之前将许多编译预先加载到运行开始时。总是有一小部分编译在流量开始之前无法初始化,因为它们依赖于仅在流量开始后才存在的状态。因此,当流量开始时,您会在 100 秒处看到编译队列中再次出现流量激增。总的来说,大约需要 8 分钟才能达到所有字节码都已重新编译的稳定点。
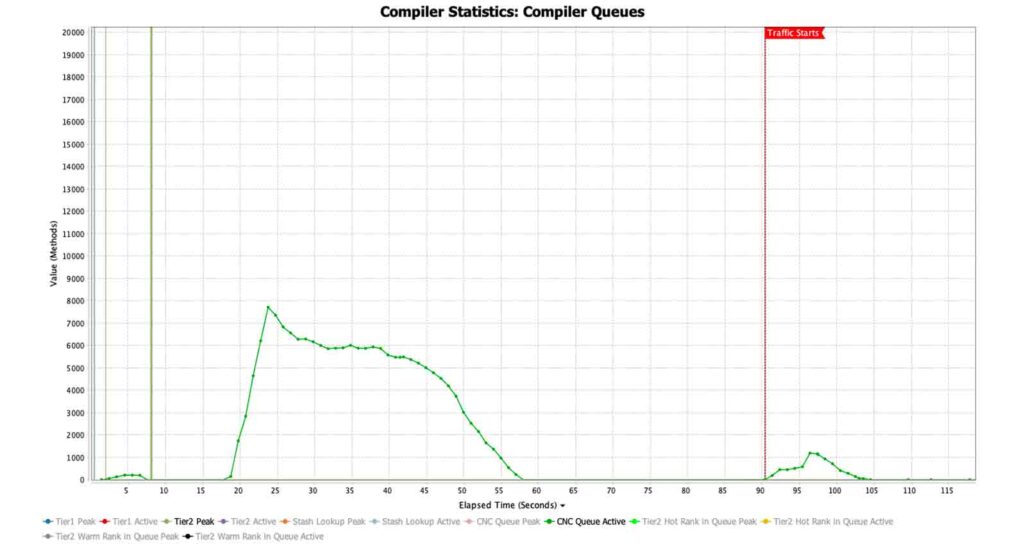
第二个图表显示了使用 Optimizer Hub 运行的同一应用程序 [图 2]。初始的流量前编译队列在约 35 秒内被完全清除。当流量开始时,这些关键方法不会被放置在长队列的末尾。相反,它们会被立即清除,从而使应用程序几乎立即达到全速。这是由两个因素导致的:
- Optimizer Hub 可以将比本地计算机上可用的线程更多的线程用于 JIT 编译
- Optimizer Hub 可以从其缓存中提供结果,而不是重新编译每个方法
结果意味着我们可以更改就绪检查,以便在 60 秒标记处提前 30 秒允许流量。
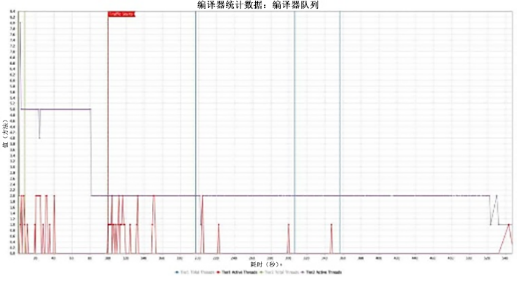
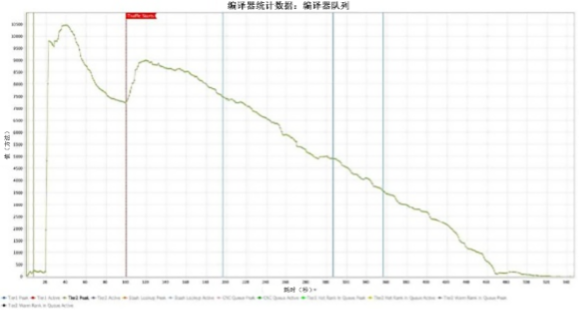
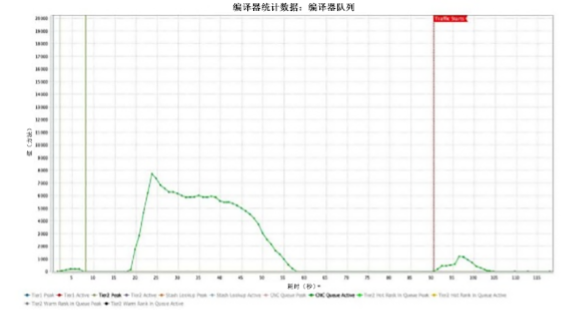
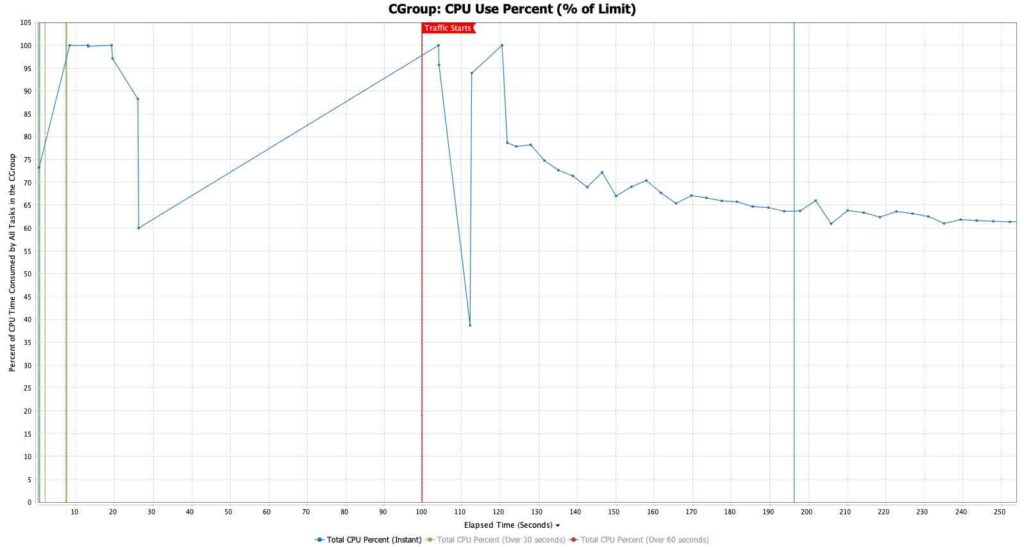
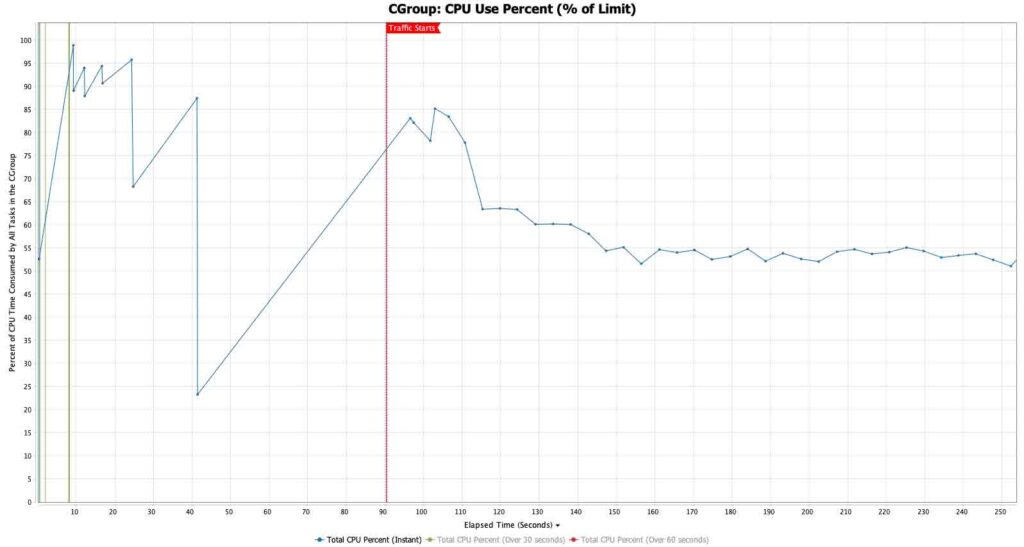
编译器线程
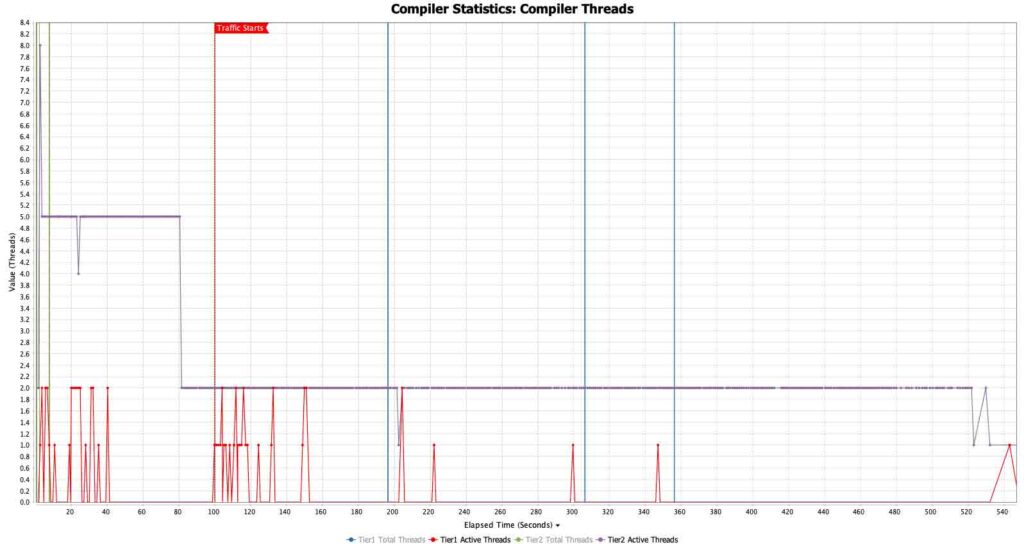
当使用本地 JIT 编译运行时,应用程序被配置为在预热期间向 JIT 编译器提供最大线程数,以便在流量开始之前完成尽可能多的编译。一旦流量开始,允许的 JIT 线程数量就会减少到两个,以确保大部分 CPU 都在处理流量。
在第一个图表中,允许的 JIT 线程数量始终处于最大状态,直到编译队列被清除 [图 3]。
在使用 Optimizer Hub 和云原生编译器的第二张图中,根本没有发生客户端第 2 层 JIT 编译 [图 4]。
CPU 使用百分比
通过 CPU 使用百分比图表,我们可以深入了解可用 vCPU 的使用情况。此处的重要变化是,在我们的 Optimizer Hub 运行中,团队将 vCore 请求从 8 个减少到 5 个。因此,在此处的 CPU 百分比图表中,Optimizer Hub 运行时的 CPU 消耗已经减少了 37.5%。
第一个图表显示了一致的高 CPU(超过分配的 8 个 vCore 的 50%)一直持续到编译队列被清除 [图 5]。然后,CPU 利用率稳定在 30% 左右,这意味着 JIT 编译完成后,70% 的容量被浪费。
第二个图表显示了从客户端移除编译活动时会发生什么情况 [图 6]。当 JVM 根本没有优化代码时,CPU 利用率仍然会出现短暂的激增,但 CPU 随后会立即稳定在所分配的 5 个 vCore 的 55% 左右。该计算机能够处理所有请求,保持在其响应时间 SLA 和 CPU 利用率自动缩放限制之内,同时减少 3 个 vCore。
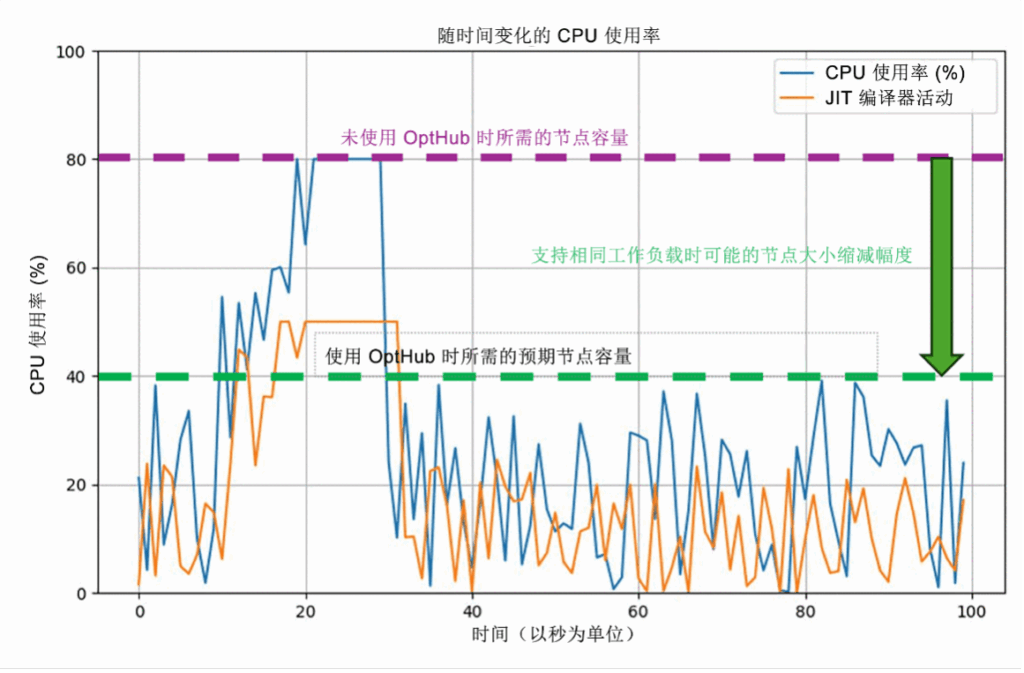
案例研究:实际影响
某大型在线零售商在应对激进的扩展需求(峰值事件期间最高需扩展至稳定状态的 20 倍)时,面临云成本与客户满意度之间的艰难权衡。他们的挑战:每当新节点加入轮换时,JVM 预热延迟就会导致事务处理速度减慢并丢失请求。
实施 Optimizer Hub 后的结果:
- 新的 JVM 已经通过共享编译进行了预热,进入了轮换阶段
- JIT 编译被整合到优化的专用机器上
- 业务节点的大小适合稳态工作负载
- 错误率和购物车放弃率大幅降低
- 被认为是“团队全年做出的最具影响力的改变”
此后,该解决方案已扩展到供应链、供应商管理和仓储系统,并实现了类似的成本降低。
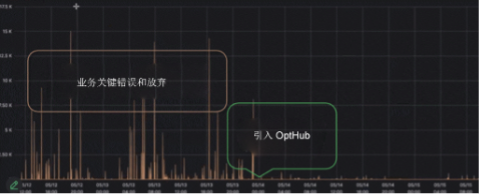
对错误的影响
下图显示了该解决方案对其最关键业务应用程序的客户满意度指标(错误/放弃率减少)的影响。正如您所看到的,这些错误的数量大大减少了。
结语
在 AWS 上运行的 Java 应用程序面临着根本性的挑战:在扩展事件和流量高峰期间,它们恰恰在您最需要的时候表现最差。传统的 JVM 预热会形成“完美风暴”:其中新实例会消耗 CPU 周期进行编译,同时尝试处理传入请求。这会导致性能下降、错误率增加以及潜在的糟糕用户体验。
Azul Optimizer Hub 通过将编译与执行分离来解决这一挑战。通过 ReadyNow Orchestrator 的共享优化配置文件和云原生编译器的专用 JIT 集群,您的 Java 应用程序从需要开始提供流量的那一刻起就可以“做好生产准备”。
如需进一步了解,请联系 Frank 或 John:



{kind=link}
{kind=link}
{kind=link}
{kind=link}