



Advantages of Microservices Architecture
Software development is always changing and, today, we see a clear shift to the use of a microservices architecture. There are a number of clear advantages to this approach, but let’s look at two of the most significant:
- Simplified deployment into the cloud. The use of containers like Docker encapsulates all the requirements for a service, from the operating system to runtime platforms to libraries and frameworks. Ensuring the right versions of libraries or even the OS are installed where the service is deployed is no longer concern. Through the use of union filesystems like AuFS, it is not necessary to replicate all files for each instance of a service (as is the case when using virtualization). This leads to savings in resources and therefore, cloud costs.
- The ability to scale applications both horizontally (at the service level) and vertically (at the application level). This scalability is dynamic, meaning service instances can be shut down when loads drop as well as started when loads increase. For cloud deployments, this is primary cost-saving consideration.
Microservices in Java
With the introduction of modularity in JDK 9, deploying Java-based microservices has become significantly more manageable through the use of tools like jlink to build a Java runtime tailored to a specific service. By only including the modules required by a service, eliminating things like manual pages and even stripping out the symbol table of the JVM, the JDK size can be reduced by an order of magnitude. Changes in JDK 10 (since backported to JDK 8 u191) mean the JVM is also CGroup-aware reducing the potential issue of an abrupt stop of the JVM when it tries to allocate more memory to the heap than it can access.
All of this makes Java an ideal platform for developing your microservices. The enormous array of libraries and frameworks available also helps to make development quicker and more straightforward.
However, using Java for microservices is not without its challenges. Let’s look at two of those:
- A transaction requested by an end-user will require the orchestration of a number of services to deliver the required result. When considering the service-level agreement (SLA) for the time it takes to complete the transaction (the latency), this is the aggregate latency of all services involved. One of the most common causes of latency in Java applications is the impact of garbage collection (GC). All production-ready algorithms (with one exception, as we’ll see), pause application threads at some point to manipulate objects in the heap in a safe way. When using multiple Java services, the cumulative latency due to GC can make it challenging to meet the user-level SLA.
- Scaling a service by spinning-up new instances as load increases depends on the responsiveness of the new instance being at the optimal level from startup. Java code is compiled into bytecodes (instructions for the Java virtual machine) rather than native instructions for the platform it runs on. This provides advantages for portability and, ultimately, performance but does require warmup time to get to full speed. The warmup time can become an issue in a very dynamic microservice architecture.
Here at Azul, we have developed the Zing JVM that solves these two issues, making Java an ideal platform for developing all applications, whether using microservices or not.
How do we do this?
Firstly, we eliminate the problem of GC pauses. Unlike other production-ready algorithms like CMS, G1, etc. we can perform all phases of GC concurrently with application threads and have compaction of the heap to eliminate fragmentation. That’s why we call our algorithm C4, the Continuous Concurrent Compacting Collector.
The key to how this works is the Loaded Value Barrier, which serves as a read barrier to all object accesses from application code. Every time the application wants to use an object, C4 will perform a test and jump; bits in the header are used to indicate the state and phase of GC. By doing this, C4 enforces two rules. Firstly, during the marking phase of GC, all objects used by the application will be marked as live data; eliminating the possibility of accidental collection of a live object. Secondly, during the relocation and remapping phases, the address of the object will be correct so that any changes made to the object state by the application will not be lost.
The graphs below show how well this works.
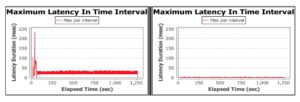
The results show the latency of the JVM running Hazelcast, the in-memory data grid, using a 1Gb heap. To produce these results, we ran the same application on the same hardware with the same workload just switching between JVMs. The jhiccup tool was used to record latency at the JVM level, and below so, no application latency had any effect. On the left, running with Hotspot, we can see GC activity resulting in almost continuous 25-40ms pauses that will dramatically reduce the response time and throughput. On the right, we can see that using Zing that there are no discernible pauses. We would need to change the scale of the graph to see the latency with Zing (much of which will be to do with things below the JVM such as OS context switching).
Deploying Zing for a chain of microservices would eliminate latency associated with GC for all of the services and make delivering the SLA for the transaction a focus on the application logic rather than the runtime platform.
For the second challenge, that of warmup time, Zing includes ReadyNow To minimize startup time, ReadyNow uses a profile collected from a previous execution of the service. The profile is collected from the service running with a representative load until all hot methods have been compiled using the Falcon JIT compiler (the code is fully warmed up). Falcon is a high-performance replacement of the C2 JIT compiler in Hotspot based on the LLVM open-source project. The ReadyNow profile records four sets of data:
- All classes currently loaded for the application.
- All classes that are initialized.
- All profiling data that was collected while C1 JIT-compiled code was run, and which was used as input to Falcon.
- All deoptimizations that occurred. One of the most significant performance gains for JIT-compiled code comes from the use of speculative optimizations. These are optimizations that assume an application will continue to behave as it has done in the past. When an assumption turns out to be incorrect, the JIT compiler must throw away the compiled code and recompile it based on the new behaviour. This is a deoptimization and is very expensive in terms of performance.
Since Falcon is fully deterministic, we know that the same inputs (method bytecodes, profiling data, etc.) will generate the same native code. We can make use of this fact, so the profile now includes all the compiled code cached by Zing at the point the profile is collected. This is called code stashing.
When a new instance of the service is started, the profile can be used to load and initialize all possible classes required and then either reuse compiled code from our stash, if appropriate or use Falcon to compile the necessary methods. All this happens before the main method of the service starts execution. The net effect is that the service will start execution at somewhere around 98% of the performance it had when the profile was collected (100% is achieved after one or two transactions have been processed). The task of scaling the service dynamically and efficiently becomes much more straightforward.
As you can see, using Zing for a microservice-based application deployed into the cloud will make the task of the development teams considerably simpler and deliver a better experience for the users.
You can try Zing free for 30 days, so why not make your microservices go zing with Zing?


